Uczyń kontakt z HBase prostszym
Każdy kto korzystał z Apache HBase zna jego podstawową wadę: brak wygody w korzystaniu z Shella. Wystarczy spróbować odczytać konkretny wiersz (row) lub zbudować warunek przy przeszukiwaniu danych aby dojść do wniosku, że autorzy mogli postarać się bardziej.
Naprzeciw tego typu problemom wychodzi HBase Simplifier (nazwa robocza) – aplikacja, która pomoże porozumieć się z HBase szybciej, prościej i… bardziej.
Na tym etapie HBase Simplifier znajduje się w fazie testów. Gdy tylko zostanie ukończona, aplikacja otrzyma swoją finalną nazwę i zostanie udostępniona szerszemu gronu w modelu komercyjnym (za jednorazową opłatą).
Jeśli jesteś Inżynierem Big Data i potrzebujesz takiej pomocy – mam znakomitą wiadomość. Możesz za darmo dołączyć do programu testerskiego. Wystarczy, że napiszesz na email (marek.czuma@protonmail.com) tytułując go „HBase Simplifier – testy”.
Jak działa HBase Simplifier?
HBase Simplifier działa jako aplikacja Apache Spark napisana w Javie.
- Uploadujesz na serwer całą paczkę,
- następnie uruchamiasz skrypt z poleceniem jako parametrem i…
- czekasz na wynik. Zwykle oczywiście szybszy, niż w przypadku zwykłego Shella.
Paczka zawiera:
- Aplikację Sparkową
- Skrypt uruchamiający
Po ukończeniu obliczeń wynik zostanie zapisany do pliku „result.csv”. Można się z nim śmiało zapoznać i wykorzystywać dalej.
Oto niektóre z możliwości, jakie daje HBase Simplifier:
Liczenie rekordów (wierszy) w tabeli (count)
Najbardziej podstawowa funkcja HBase Simplifier to count – czyli liczenie wierszy w tabeli.
Podstawowy count
Zacznijmy od najbardziej bazowej wersji, czyli swojskiego counta wszystkich elementów w tabeli. Uruchamiamy to tak jak na poniższym obrazku.
![]()
Jak widać wszystko jest jasne – count_records określa działanie, następnie musimy wskazać o jaką tabelę chodzi i voila!
Tabela z tweetami jest duża, możemy więc śmiało zrobić sobie kawę lub nawet pójść z Żoną na obiad do restauracji. Efekt (processingu, nie obiadu) zostanie zapisany do result.csv. W tym przypadku jest następujący:

Całość może być nawet kilkukrotnie szybciej przeprocesowana, niż przy korzystaniu z HBase Shell. Oczywiście to jak dużo szybciej – zależy od ustawień wydajnościowych (rozdział niżej).
Count z warunkiem typu „where”
Tu HBase Simplifier nabiera rumieńców. Przypuśćmy, że chcemy wyszukać jedynie takie tweety, które będą napisane po polsku. Żaden problem:
![]()
Count z warunkiem typu „timestamp”
Oczywiście może także zdarzyć się i tak, że chcemy przefiltrować wyniki biorąc pod uwagę nie zawartość, ale czas kiedy wiersz został dodany do tabeli. Oto jak poradzić sobie z tym problemem przy użyciu HBase Simplifier:
![]()
Inne funkcje działające na podobnych zasadach
Powyżej wskazałem schemat działania języka poleceń stworzonego na potrzeby HBase Simplifier. Na analogicznej zasadzie działają także inne funkcjonalności:
- Usuwanie rekordów (remove_records) – usuwanie rekordów z tabeli. Można wszystkie, można z warunkiem.
- Update rekordów (massive_update_records) – masowa zmiana wartości w tabeli. Oto przykład działania:

- Wyświetlanie wyników (scan) – zmora HBase Shell, czyli scanowanie wierszy. W przypadku konsoli HBase’owej mamy do czynienia z niewygodnym interfejsem. HBase Simplifier cywilizuje nieco możliwość przeglądania wyników. Poniższy przykład pokazuje polecenie wyświetlenia wyników w zależności od timestampu.
 Tak wygląda natomiast wynik (a właściwie jego fragment) zwrócony przez aplikację (oczywiście zapisany w pliku result.csv).
Tak wygląda natomiast wynik (a właściwie jego fragment) zwrócony przez aplikację (oczywiście zapisany w pliku result.csv).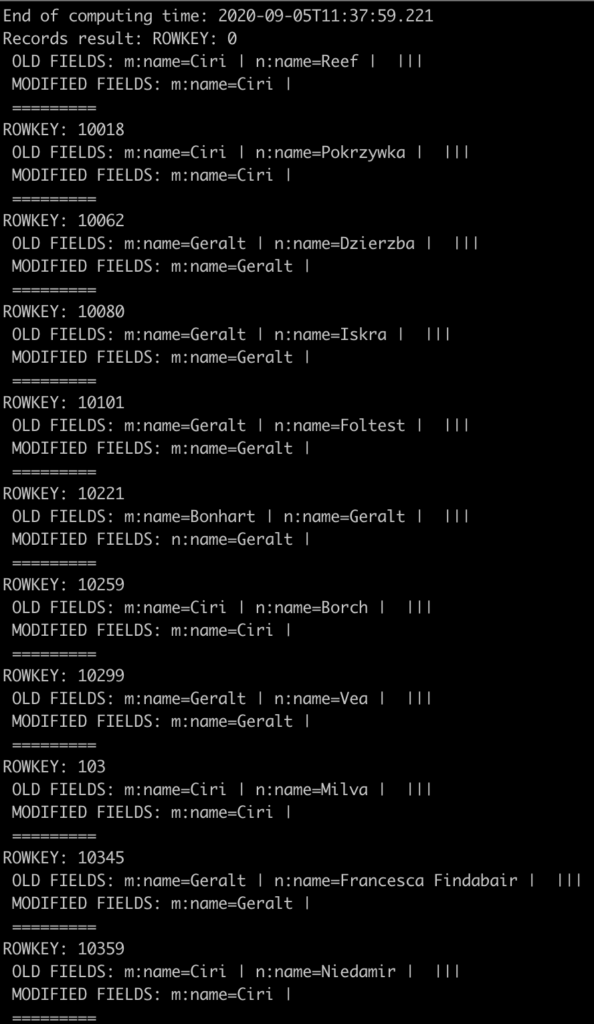
- Kopiowanie tabeli (copy_table) – korzystając z HBase Simplifier dysponujemy możliwością skopiowania tabeli. I możemy oczywiście wykorzystać do tego także wyżej wymienione filtry.
Tworzenie nowej tabeli
Ostatnią funkcją, którą udostępnia HBase Simplifier jest tworzenie nowej tabeli (polecenie generate_table). Oto jak wygląda wywołanie skryptu, który zrobi rzeczoną robotę:
![]()
Jak widać musimy podać następujące wartości:
- Namespace oraz nazwę tabeli
- Column Families
- Liczbę rekordów (po „records:”).
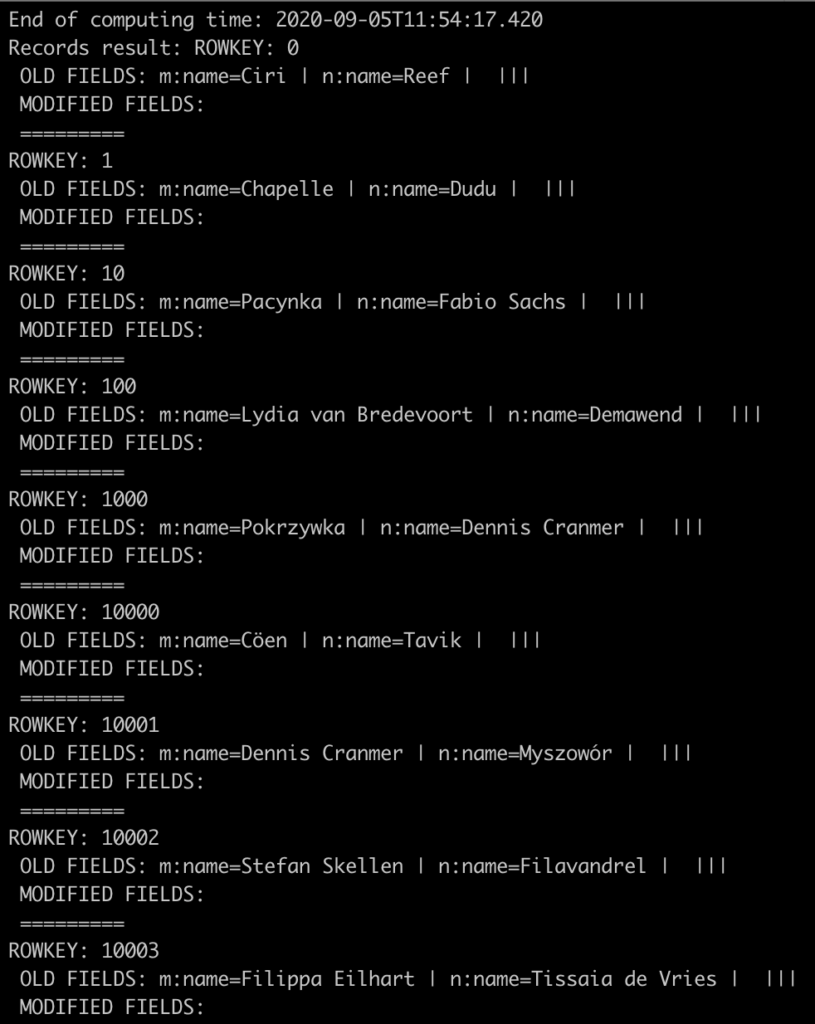
Po uruchomieniu HBase Simplifier stworzy tabelę z podanymi wymaganiami (musimy dopilnować, aby nie istniała wcześniej), a następnie wypełni ją przykładowymi danymi.
W tym miejscu może się pojawić zasadne pytanie – czym są owe „przykładowe dane?”. Śpiesząc z odpowiedzią podaję: HBase Simplifier wypełnia tabelę… imionami bohaterów powieści „Wiedźmin”;-).
Efekt (jego fragment) można obserwować poniżej:
Zmiana ustawień wydajnościowych
Cała aplikacja jest jobem Sparkowym. W związku z tym ustawienia dotyczące tego jakie zasoby mają zostać wykorzystane oczywiście są dostępne.
W tym celu należy przejść do skryptu uruchamiającego „run.sh”. Tu można już dowolnie manipulować zasobami w zależności od możliwości jakie oferuje klaster.
Przetestuj HBase Simplifier za darmo!
Obecnie aplikacja jest w fazie testów. Po jej zakończeniu można będzie ją pobrać za jednorazową opłatą. W tym momencie jednak można zapisać się do programu testów i za darmo korzystać z aplikacji.
Aby to uczynić zachęcam do kontaktu na email „marek.czuma@protonmail.com” – wiadomość zatytułuj „HBase Simplifier – testy”. Jestem przekonany, że HBase Simplifier uczyni Twoje życie prostszym, zaś Ty pomożesz mi w lepszym budowaniu aplikacji.
Marek Czuma
Autorzy
Architekt i główny twórca: Marek Czuma
założyciel RDF
Inżynier Big Data
Konsultant (implementacja): Łukasz Okrąglewski
konsultant RDF
Inżynier Big Data
Konsultant (architektura): Maciej Moradewicz
konsultant RDF
Inżynier Big Data