Na skróty
Cel: Zbudować prototyp systemu wspierającego analizę Twittera.
Technologie i techniki: Apache Spark, HBase, Hadoop (Hortonworks), Solr, Scala, Java, Spring Boot, Machine Learning
Efekt końcowy: Aplikacja analityczna będąca inteligentną wyszukiwarką (rys. 1).
Twitter – miejsce dyskusji pod lupą Big Data
Współcześnie coraz więcej wiedzy o ludziach oraz sytuacji społeczno-politycznej umieszczane jest w mediach społecznościowych. Niestety – nie jest to wiedza widoczna „gołym okiem”. Aby ją zdobyć trzeba spojrzeć „z góry”, analizować i zestawiać ze sobą rzeczy, które osobno nie tworzą żadnego spójnego obrazu.
Celem projektu było zbudowanie prototypu systemu, który pomaga wziąć pod lupę Twittera – jedno z największych współczesnych miejsc dyskusji.
Cel udało się zrealizować w stopniu bardzo dobrym – zapraszam na opis systemu, jego architektury oraz infrastruktury technologicznej, która umożliwia jego pracę.
Aplikacja Analityczna (wyszukiwarka)
Choć sama aplikacja jest jedynie „wierzchołkiem góry lodowej”, pozwala (dzięki swojej prostocie) błyskawicznie zrozumieć sens i zamysł całego systemu.
Aplikacja jest tak naprawdę rozbudowaną, 3-modułową wyszukiwarką. Pozwala na przeszukiwanie wyników wcześniej dokonanej analizy tweetów oraz użytkowników Twittera. Moduły te dotyczą:
- szukania tweetów,
- szukania użytkowników,
- przeglądania profilu konkretnego użytkownika (i jego tweetów)
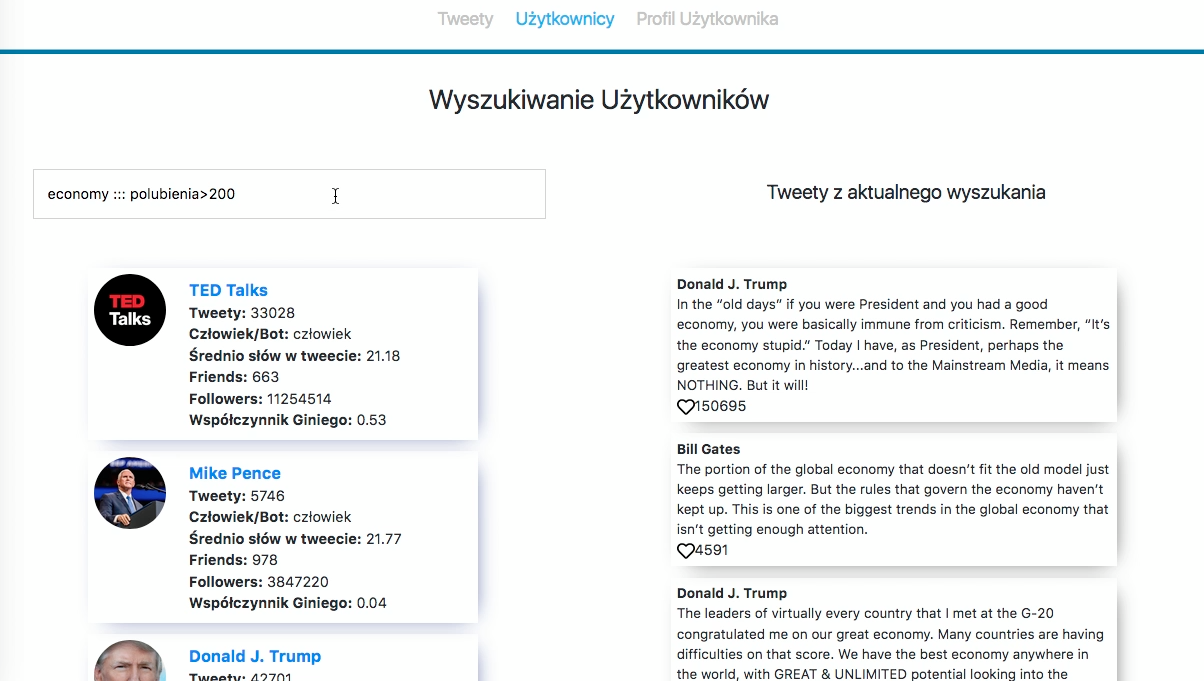
Poza standardowym wyszukiwaniem (z zaimplementowaną funkcją uwzględniania literówek oraz „domyślania się” niepełnych wyrazów) analityk ma możliwość zastosowania filtrów. Na rysunku 1 widać jedno z wielu możliwych zastosowań tego mechanizmu (popularne tweety z frazą „economy”). Poza tym jednak można wyszczególnić autora, sentyment treści (pozytywny, negatywny?) czy język w jakim tweet został opublikowany oraz inne.
W profilu konkretnego użytkownika znajdziemy zbiorcze wyniki analizy (pod jego kątem) oraz tweety, których jest autorem. Zobaczymy więc m.in. czy system podejrzewa użytkownika o bycie botem, a także jaki jest współczynnik giniego pod względem popularności tweetów. To bardzo autorski pomysł, który w prosty sposób pozwala określić stałość w popularności danego autora.
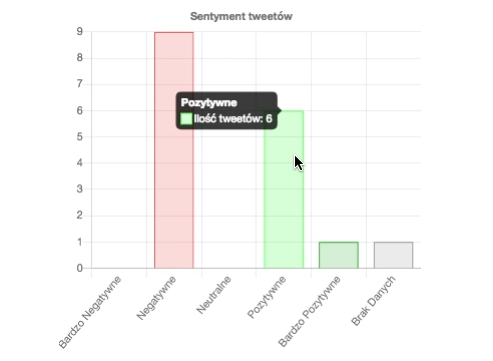
Zarówno w module z wyszukiwaniem tweetów jak i w profilu użytkownika, analityk korzystający z aplikacji ma do dyspozycji statystyki. Te dotykają takich kwestii jak ilość opublikowanych tweetów w czasie, rozkład sentymentu i inne.
Aplikacja jest niewątpliwie „twarzą” całego systemu. Jest jednak – obiektywnie patrząc – bardzo skromną jego częścią. To pod nią kryje się cały złożony mechanizm.
Analizator Twittera – architektura systemu Big Data
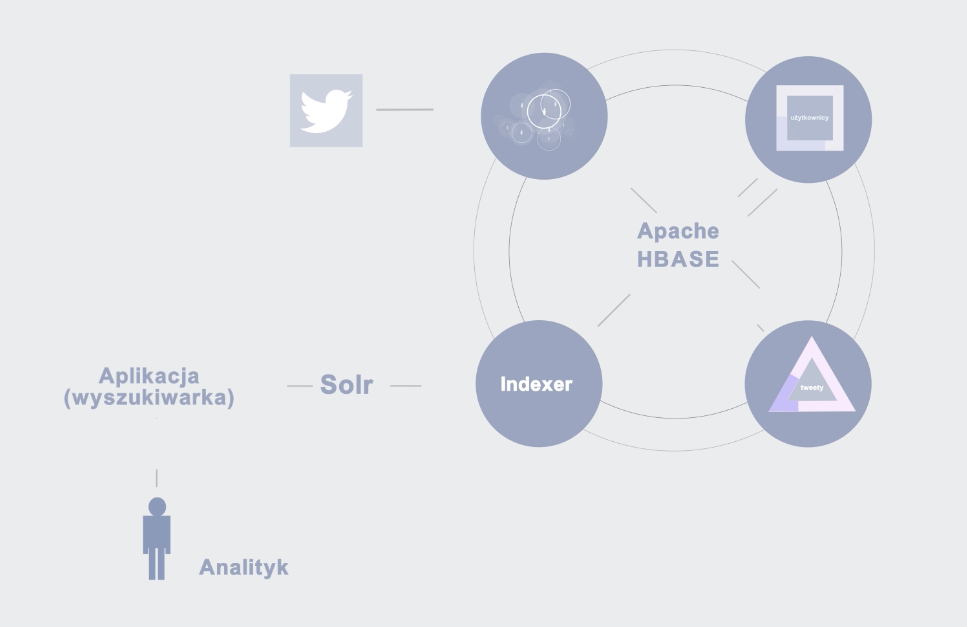
System napisany został w języku Scala. Zbudowany jest z 5 autonomicznych modułów (4 stricte zajmujące się danymi + Aplikacja Analityczna). Moduły te mogą działać dzięki infrastrukturze technologicznej zbudowanej na klastrze Apache Hadoop w dystrybucji Hortonworks. Poniższa grafika pokazuje w jaki sposób cały system został zbudowany i zintegrowany.
Pobieranie danych z Twittera
Pierwszy moduł odpowiada za pobranie danych z Twittera. Do tego celu zbudowany został mechanizm, który działa w dwóch wątkach.
Pierwszy z nich pobiera użytkowników, którymi jesteśmy zainteresowani. Zaczyna od wskazanego użytkownika i najpierw to jego dane lądują w bazie. Następnie na tapet brani są ludzie z jego otoczenia (jak followersi czy friendsi). Zbierane są wszystkie dane, które udostępniane są przez portal.
W drugim wątku działa mechanizm odpowiedzialny za pobranie wszystkich danych związanych z tweetami już pobranych użytkowników.
Dzięki takiemu mechanizmowi zawsze będziemy mieli więcej użytkowników, niż ich statusów (tweetów). Pozwala to najpierw budować sieć społeczności, która następnie jest stopniowo coraz bardziej uzupełniana.
Wszystkie dane pobierane są przy pomocy biblioteki Twitter4J i trafiają do Apache HBase.
Przetwarzanie tweetów
Drugi moduł odpowiada za przetwarzanie statusów (tweetów). Wszystkie obliczenia wykonywane są na infrastrukturze zbudowanej dzięki Apache Spark, który pozwala na optymalne, zrównoleglone wykonywanie operacji.
W ramach przetwarzania statusów sprawdzany jest m.in. sentyment anglojęzycznych wiadomości (od bardzo-negatywnego do bardzo-pozytywnego). Aby to zrobić wykorzystałem bibliotekę StanfordNLP.
Całość po przeprocesowaniu znów zapisywana jest w HBase.
Przetwarzanie użytkowników
To prawdopodobnie najistotniejszy, kluczowy moduł całego systemu. By zdobyć odpowiednie informacje o użytkownikach, wykorzystywane są dane o nich bezpośrednio z Twittera oraz przetworzone wcześniej tweety.
Przede wszystkim obliczane są podstawowe dane statystyczne, takie jak średnia ilość wyrazów na tweet dla danego użytkownika czy średni sentyment tweetów.
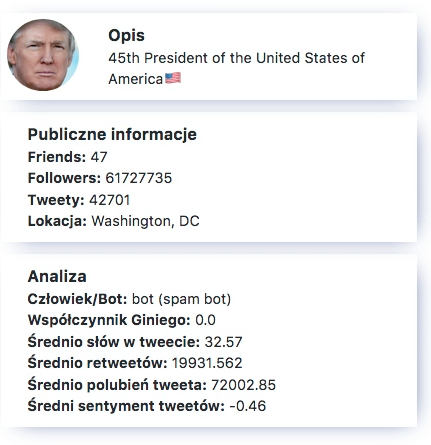
Niewątpliwie autorskim pomysłem jest obliczanie Współczynnika Giniego dla popularności tweetów danego autora. W teorii współczynnik ten mierzy koncentrację wartości na podanej przestrzeni. Najczęściej wykorzystuje się go do badania nierówności dochodowych. W RDF-owym Analizatorze Twittera Współczynnik pełni rolę testu na stabilność popularności. Dzięki niemu dowiemy się, czy autor posiada stałą popularność wśród innych użytkowników, czy jedynie udaje mu się ją zdobyć raz na jakiś czas.
Jednym z istotniejszych (i dla wielu najciekawszym) elementów jest proces przewidywania, czy użytkownik jest botem. Jest to algorytm machine learning, który najpierw na podstawie wielu tysięcy przypadków nauczył się które konta można nazwać botami, a które nie. Następnie – korzystając z przygotowanego modelu – typuje „podejrzenie bycia botem” w odniesieniu do konkretnych, przetwarzanych użytkowników (warto podkreślić słowo podejrzenie).
Całość przetworzonych danych ponownie zapisywana jest do bazy danych Apache HBase. Wszystko odbywa się dzięki technologii Apache Spark, zaś typowanie botów przeprowadzone jest przy użyciu metody Random Forests.
Indexer
Ostatnim modułem jest indexer. Jest najmniejszym ze wszystkich mechanizmów i odpowiada za przeniesienie potrzebnych danych z Apache HBase do Solr.
Dzięki zastosowaniu silnika przeszukiwania pełnotekstowego (full-text-search engine) system zyskał dodatkowe możliwości. To właśnie Solr odgrywa kluczową rolę w Aplikacji Analitycznej.
Analityk, który z niej korzysta, tak naprawdę nieustannie wysyła zapytania do Solr. Mimo dużych ilości danych, pożądane treści można znaleźć szybko i w inteligentny sposób (np. radząc sobie z literówkami), a także odpowiednio przedstawić (między innymi w formie odpowiednich wykresów).
Wnioski – czyli w jakim świecie żyjemy?
Celem było zbudowanie prototypu systemu wspierającego analizę Twittera. Cel ten udało się zrealizować w 100%. Wnioski po zrealizowaniu go podzieliłem na dwie grupy: techniczne i nietechniczne – dotykające nas wszystkich.
Bardzo istotnym wnioskiem technicznym płynącym z prac nad Analizatorem jest nieoceniona wartość budowania modułowego. System Big Data jest z definicji złożonym mechanizmem. Zbudowanie go wymaga niezwykłej staranności na etapie projektowania, ponieważ konieczne jest sprawne skoordynowanie wszystkich modułów. Trzeba pamiętać o tym, jednak przykładając się do tego pierwszego etapu oszczędzić można zespołowi inżynierów ogromu niepotrzebnej, żmudnej pracy.

Drugi wniosek jest mniej techniczny. Warto zastanowić się nad samą naturą prowadzonych prac. Mowa jest o olbrzymim portalu społecznościowym, gdzie użytkownicy dzielą się swoimi przemyśleniami na wszelakie tematy. Już tutaj, nawet wykonując jedynie prototyp systemu, można wyciągnąć dość daleko idące wnioski i dokonać wstępnego profilowania.
Warto więc zastanowić się, co można wyciągnąć łącząc wiele takich miejsc jak Twitter i poświęcając ogromne środki (pieniężne i czasowe) na monitorowanie ich i wyciąganie przydatnych informacji. To baza wiedzy o której agencje wywiadowcze na całym świecie, w całej historii ludzkości nawet nie marzyły. Informacje zebrane w ten sposób mogą posłużyć rozmaitym grupom do wszelakich celów. Warto, abyśmy byli tego świadomi, gdy publikujemy kolejne treści na temat naszego życia osobistego w Internecie.
Autor: Marek Czuma
założyciel RDF
Inżynier Big Data