Cel: Zbudować prototyp systemu sterującego ruchem „łazików marsjańskich”
Technologie i techniki: Scala, Apache Spark (Spark Structured Streaming), Apache Kafka, Apache HBase, Streaming
Łaziki marsjańskie i rozmowa techniczna – pomysł na wyzwanie
Czasami tak bywa, że programista potrzebuje nagłego, krótkiego, ale intensywnego wyzwania. Spełnieniu tego typu „zachcianek” służą hackathony. To wydarzenia podczas którego specjaliści z szeroko pojętej branży IT w ciągu X godzin (zwykle ~2 doby) muszą skonstruować działający prototyp odpowiadający na jakieś zadanie/wyzwanie. Jakiś czas temu tego typu pragnienie pojawiło się także u mnie
Podczas jednej z rozmów technicznych dostałem zadanie, które miało za zadanie sprawdzić jedynie styl myślenia (czasu było ~10 minut, więc rozwiązanie go w 100% było niewykonalne). Przedstawione było w grafice, więc i ja wklejam ową grafikę poniżej.

Po zakończeniu rozmowy do głowy wpadł mi pomysł, aby rozwinąć wyżej wymienione zadanie i napisać w formie prototypu. Zadanie miało nabrać znamion problemu Big Data, zaś rozwiązanie miało zająć nie więcej niż kilka dni (najlepiej 2 – sobotę i niedzielę, ale zostawiałem sobie możliwość rozszerzenia także na tydzień).
W ten sposób zaprojektowałem coś w stylu „self-hackathonu”. Zdawałem sobie sprawę, że tego typu proste zadanie programistyczne po rozwinięciu do moich założeń musi mieć trochę wymuszony kształt. Zdawałem sobie również sprawę z tego, że rozwiązania mogą odbiegać od ideału.
Założenia
W ten sposób dochodzimy do założeń projektu. Opisałem je w sobotę rano i brzmiały one następująco:
- Projekt to centrum sterowania ruchem łazików marsjańskich
- X łazików startuje z losowego punktu na mapie
- Wysyłają one plan podróży na następne 5 kroków (NWSE, każdy krok idzie jednż jednostkę w przestrzeni i zajmuje 2 minuty) – to powinno być losowe
- System na bieżąco odbiera te plany i zarządza nimi – odpowiada konkretnemu łazikowi czy może iść konkretny krok czy ma poczekać, a jesli tak to ile czasu.
- Następnie łazik idzie zgodnie z pozwoleniem systemu.
- Przy okazji zbierane są dane które potem mogłyby generować statystyki – na przykład przy jakiej liczbie łazików ile sumarycznie musiały czekać po 30 minutach trwania.
Projektowanie
Gdy skończone już były założenia, można było śmiało podejść do zgrubnego zaprojektowania architektury systemu. Wnioski z poprzednich systemów są takie, że bardzo istotne jest, aby możliwie dużo zaprojektować na początku. Choć wydaje się to oczywiste, nawet w dużych komercyjnych projektach niekiedy prace rozpoczynane są jedynie z ogólnym zarysem. W trakcie dokładane są coraz to kolejne funkcjonalności, zaś generalna specyfikacja powstaje pod koniec (przykład z życia wzięty;-)). Nie należy to do dobrych praktyk, a ponadto często świadczyć może o braku życiowego, biznesowego zapotrzebowania na taki produkt (choć moim zdaniem niezbędny jest także pewien dystans i elastyczność w trakcie tworzenia).
Tak więc – choć tym razem projekt miał charakter stricte „hackathonowy”, architektura (a nawet część algorytmów) rozpisana została wcześniej. Mimo, że forma finalna niekoniecznie może zostać podana za wzór dokumentu korporacyjnego, swoje zadanie spełniała idealnie. Zapiski sporządzane były na tablicy suchościeralnej oraz kartkach papieru;-).
Uproszczona architektura systemu
Cały projekt sterowania ruchem zmieszczony został w jednym scalowym (sbt), projekcie – a konkretniej w jobie sparkowym (moduł „Center”). Tutaj wykonywane są wszystkie decyzyjne obliczenia i porównania.
Pozostaje jednak jeszcze kwestia samych łazików. Wszak w normalnym świecie to pojedyncze jednostki wysyłałyby informacje! Tym razem jednak (wyjątkowo) nie dysponowałem prawdziwymi łazikami marsjańskimi. Poradziłem sobie z tym fantem tworząc moduł symulujący działanie dowolnej (podanej) liczby łazików. Miał on za zadanie obsługę łazików (a więc „poruszanie się”, generowanie nowego planu, oczekiwanie) oraz komunikację ze światem zewnętrznym – czyli wysyłanie planów, współrzędnych, odbieranie odpowiedzi itd.
Gdy oba moduły zostały zaprojektowane, należało pomyśleć nad tym jak je skomunikować. Absolutnie naturalnym wyborem była technika streamingu danych – zarówno pytań jak i odpowiedzi. W tym miejscu wybrałem Kafkę (Apache Kafka). Po części dlatego, że od dawna już chciałem poznać tą technologię (wcześniej miałem z nią tylko lekką styczność), do tego jest popularna (co daje duży atut w postaci rozbudowanej społeczności) i ma niski próg wejścia (szczególnie z unixowymi systemami).
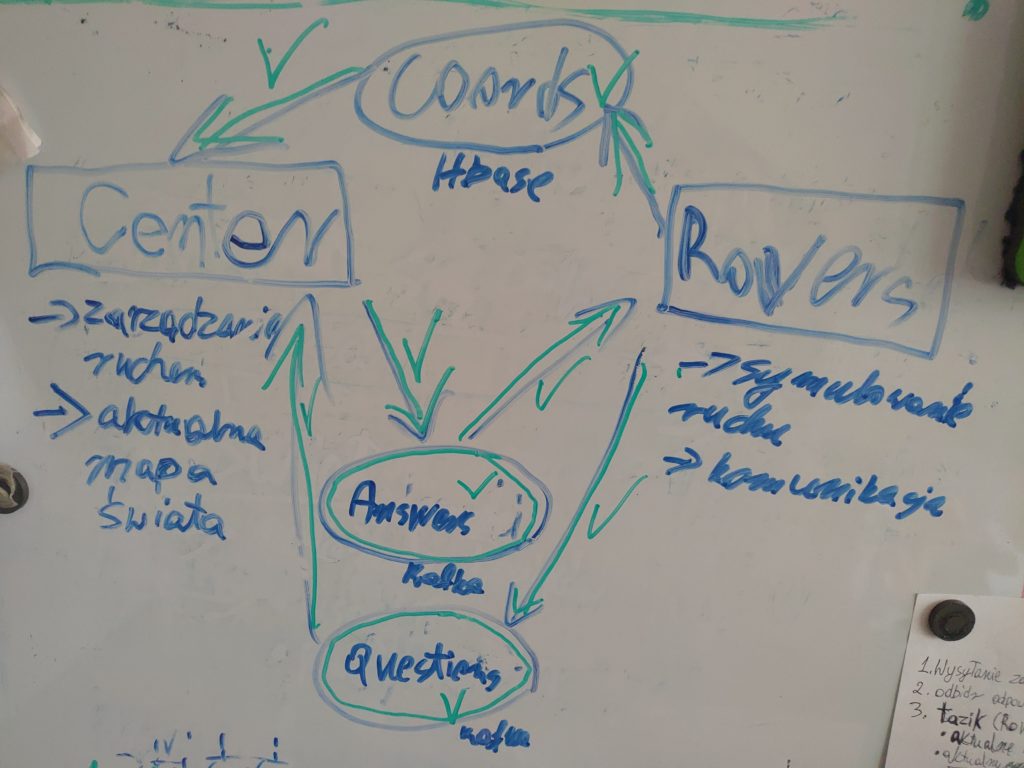
Na koniec pozostał jeszcze jeden brakujący element. Otóż w paru miejscach systemu potrzebowałem dysponować na bieżąco aktualnym „stanem świata”, czyli koordynatami wszystkich łazików (a najlepiej także ich planami). Przez jakiś czas rozważałem Kafkę, jednak finalnie zdecydowałem się na zaprzęgnięcie do pracy nierelacyjnej bazy Apache HBase. Tutaj atutem była moja solidna znajomość tematu i dobra biblioteka (SHC) pozwalająca w wygodny sposób pobrać całą tabelę do sparkowego DataFrame.
Implementacja
Jest architektura, czas zabrać się za implementację.
Moduł Center
Zacznijmy od najważniejszego punktu – czyli modułu nazwanego przeze mnie „Central”. To właściwa część całego systemu, tam dokonywane były wszystkie obliczenia i porównania.
Stworzony został jako job Sparkowy (Apache Spark) napisany w Scali. Jeśli czytelnik chętny jest na zgłębienie kodu, zacząć należy od klasy CollisionsStreaming – zawiera ona streamingowy pipeline który jest głównym trzonem aplikacji. Dostępna tutaj.
Całe działanie zaczyna się od consumera kafki, który pobiera zapytania. Podawane są one w formacie „{rover_id}-{current_coordinates}-{directions}” , na przykład „1-10,12-NNWNW”.
Następnie wykonywane są wszystkie obliczenia, by na końcu dane znów wróciły do kafki. Aby to jednak zrobić używam customowy sink zamiast gotowego sinka kafkowego. Wymuszone zostało to przez potrzebę odwołania się do zewnętrznych DataFramów, co zrobić można jedynie w sinku. Odpowiedź ma format „{rover_id}-{timeouts}” na przykład „1-0,0,2,4,0”.
Poza tym jednak interesującym elementem modułu jest klasa GeneralCoordinates (dostępna tutaj).( Odpowiada ona za systematyczne pobieranie aktualnego stanu świata zapisanego w HBase w tabeli „mrtc:coordinates”. Aby to uczynić używam biblioteki SHC, która pozwala w prosty sposób zaczytać całość z bazy i umieścić automatycznie w sparkowym DataFrame.
Moduł Rovers-Simulator
To moduł, w którym zaimplementowane jest sterowanie łazikami. Zacząć warto od klasy RoversManager, bo to tam właśnie zaimplementowane są metody sterujące (do przeczytania tutaj). Klasa działa w nieskończonej pętli podczas której iteruje po wszystkich łazikach i wykonuje na nich metodę runIfPossible(). Do tego co kilka sekund sprawdza, czy są jakieś nowe pytania do centrali i jeśli tak – wysyła je.
Warte uwagi są także klasy zawierające consumer i producer kafkowy – AnswerStreaming i QuestionsStreaming. Obie można zobaczyć tutaj.
Kafka
Kafka postawiona została z udziałem dwóch topiców – questions oraz answers. Na jednym z nich nasłuchuje moduł centralny (i wrzucane są tam pytania od łazików – tu łaziki dostarczałyby pytania osobiście, gdyby nie były systemem symulującym), zaś na drugim symulator łazików.
Wnioski
Uważam, że dobre zakończenie każdego projektu, to spisanie konkretnych wniosków bazujących na doświadczeniach z niego. Tu chciałbym się skupić na tym co poszło nie tak (i co byłoby niedopuszczalne w normalnym systemie), co zapisuję sobie na plus, co można wyciągnąć na przyszłość.
Co poszło nie tak
Zacznijmy od skonfrontowania się z kilkoma rzeczami, które ewidentnie nie mogłyby być zaakceptowane, gdybyśmy pracowali nad prawdziwym docelowym systemem.
Przede wszystkim minusem są rozwiązania tymczasowe w kontekście scali. Wiele z nich nie spełniało założeń programowania funkcyjnego. Widać spore kompromisy i pójście na skróty.
Kolejną kwestią jest architektura streamingowa. Choć jest to całkowicie wybaczalne (ze względu na hackathonowy charakter projektu oraz pierwsze zderzenie z Kafką i Spark Structured Streaming), to przez nieprawidłowo zaprojektowaną architekturę część operacji musiała zostać „upchnięta” w customowym sinku, co nie jest dobrą praktyką.
Wreszcie – po trzecie – algorytm decyzyjności pozostawia wiele do życzenia. Mogą zdarzać się kolizje, nie jest prawidłowo uwzględniana aktualna pozycja łazików (uwzględniana jest jedynie częściowo), zaś obliczanie różnic czasowych trwa na tyle długo, że konieczne jest użycie odpowiednio mocnych maszyn, aby wszystko przebiegało sprawnie. To tak naprawdę wąskie gardło algorytmu. Może się bowiem okazać, że algorytm decyzyjności trwa na tyle długo, że obliczone czasy są nieadekwatne do realiów.
Co można zapisać na plus
Warto jednak zauważyć kilka elementów, które wyszły satysfakcjonująco.
Przede wszystkim – w bardzo krótkim czasie udało się zbudować system o sporej złożoności. W końcu mamy tu dwa moduły, Sparka, Kafkę, HBase, jest zaprzęgnięty streaming – i to wszystko razem jest zgrane, komunikuje się i nie popełnia błędów zatrzymujących program (testowane przez ok. 30 minut pod rząd).
Drugą sprawą jest clean code – choć czasu było bardzo mało, kod w większości utrzymany jest schludnie. Przywiązuję do tego dużą wagę w projektach większych, komercyjnych, jednak i tutaj uważam, że dobrze jest stawiać na jakość.
Ostatnia rzecz to złożoność algorytmiczna – w bardzo krótkim przedziale czasu należało zaprojektować, a potem zaimplementować algorytmy, które nie należały do trywialnych. Wystarczy powiedzieć, że algorytm decyzyjności operować musiał na przestrzeni trójwymiarowej (2 wymiary przestrzeni + 1 wymiar czasu) uwzględniając wiele punktów położonych w niej, z czego jeden wymiar musiał być potraktowany obszarowo (nie można było sprawdzać precyzyjnie czasu, a raczej obszar wokół punktów czasowych). Zaprojektować, a następnie zaimplementować należało także wiele mniejszych mechanizmów i to wszystko się udało.
Co zapamiętać na przyszłość?
Do zapamiętania na przyszłość z pewnością kilka rzeczy:
- Po pierwsze – dobrze zaprojektowana architektura to podstawa. Nie musi być zrobiona na formalnym korporacyjnym dokumencie, jednak musi być przejrzysta i spójna. Dobrze jeszcze przed implementacją zasymulować różne problemy i działania, które z pewnością wykażą lukę w rozumowaniu.
- Kafka jest dobrym narzędziem. I jeśli chcemy korzystać ze streamingu, to przechodzi mój test. Test ten polega na prostej rzeczy: „jak technologia spełnia podstawowe funkcje”? Kafka proste rzeczy robi dobrze i w prostych rzeczach działa dobrze. To bardzo istotne, bowiem często mamy do czynienia z „kombajnami”, które odstraszają podstawowymi błędami.
- To już wniosek poza techniczny. Nawet w okresach o ogromnej intensywności warto dobrze zarządzać odpoczynkiem i „wyciskaniem się”. Moja produktywność mogłaby być większa, gdybym to lepiej robił. Choć i tak było nieźle;-)
Podsumowanie
Podsumowując: To był wspaniały (choć krótki) czas, gdy mogłem podjąć rzuconą przez siebie rękawicę i zaprojektować system od 0, a następnie go zaimplementować. Czekało mnie trochę wyzwań algorytmicznych, konkretna dawka nauki i mnóstwo pracy. Zabawa jednak się udała i pozytywnie wpłynęła na poziom moich umiejętności, co w gruncie rzeczy jest najważniejsze;-)
Projekt dostępny publicznie na Githubie: https://github.com/marekczuma/mrtc
Autor: Marek Czuma
założyciel RDF
Inżynier Big Data